Mining Texts to Generate Fuzzy Measures of Political Regime Type at Low Cost
Mining Texts to Generate Fuzzy Measures of Political Regime Type at Low Cost. Reposted from Dart Throwing Chimp, by Jay Ulfelder.
Political scientists use the term “regime type” to refer to the formal and informal structure of a country’s government. Of course, “government” entails a lot of things, so discussions of regime type focus more specifically on how rulers are selected and how their authority is organized and exercised. The chief distinction in contemporary work on regime type is between democracies and non-democracies, but there’s some really good work on variations of non-democracy as well (see here and here, for example).
Unfortunately, measuring regime type is hard, and conventional measures of regime type suffer from one or two crucial drawbacks.
First, many of the data sets we have now represent regime types or their components with bivalent categorical measures that sweep meaningful uncertainty under the rug. Specific countries at specific times are identified as fitting into one and only one category, even when researchers knowledgeable about those cases might be unsure or disagree about where they belong. For example, all of the data sets that distinguish categorically between democracies and non-democracies—like this one, this one, and this one—agree that Norway is the former and Saudi Arabia the latter, but they sometimes diverge on the classification of countries like Russia, Venezuela, and Pakistan, and rightly so.
Importantly, the degree of our uncertainty about where a case belongs may itself be correlated with many of the things that researchers use data on regime type to study. As a result, findings and forecasts derived from those data are likely to be sensitive to those bivalent calls in ways that are hard to understand when that uncertainty is ignored. In principle, it should be possible to make that uncertainty explicit by reporting the probability that a case belongs in a specific set instead of making a crisp yes/no decision, but that’s not what most of the data sets we have now do.
Second, virtually all of the existing measures are expensive to produce. These data sets are coded either by hand or through expert surveys, and routinely covering the world this way takes a lot of time and resources. (I say this from knowledge of the budgets for the production of some of these data sets, and from personal experience.) Partly because these data are so costly to make, many of these measures aren’t regularly updated. And, if the data aren’t regularly updated, we can’t use them to generate the real-time forecasts that offer the toughest test of our theories and are of practical value to some audiences.
As part of the NSF-funded MADCOW project*, Michael D. (Mike) Ward, Philip Schrodt, and I are exploring ways to use text mining and machine learning to generate measures of regime type that are fuzzier in a good way from a process that is mostly automated. These measures would explicitly represent uncertainty about where specific cases belong by reporting the probability that a certain case fits a certain regime type instead of forcing an either/or decision. Because the process of generating these measures would be mostly automated, they would be much cheaper to produce than the hand-coded or survey-based data sets we use now, and they could be updated in near-real time as relevant texts become available.
At this week’s annual meeting of the American Political Science Association, I’ll be presenting a paper—co-authored with Mike and Shahryar Minhas of Duke University’s WardLab—that describes preliminary results from this endeavor. Shahryar, Mike, and I started by selecting a corpus of familiar and well-structured texts describing politics and human-rights practices each year in all countries worldwide: the U.S. State Department’s Country Reports on Human Rights Practices, and Freedom House’s Freedom in the World. After pre-processing those texts in a few conventional ways, we dumped the two reports for each country-year into a single bag of words and used text mining to extract features from those bags in the form of vectorized tokens that may be grossly described as word counts. (See this recent post for some things I learned from that process.) Next, we used those vectorized tokens as inputs to a series of binary classification models representing a few different ideal-typical regime types as observed in few widely used, human-coded data sets. Finally, we applied those classification models to a test set of country-years held out at the start to assess the models’ ability to classify regime types in cases they had not previously “seen.” The picture below illustrates the process and shows how we hope eventually to develop models that can be applied to recent documents to generate new regime data in near-real time.
Overview of MADCOW Regime Classification Process
Our initial results demonstrate that this strategy can work. Our classifiers perform well out of sample, achieving high or very high precision and recall scores in cross-validation on all four of the regime types we have tried to measure so far: democracy, monarchy, military rule, and one-party rule. The separation plots below are based on out-of-sample results from support vector machines trained on data from the 1990s and most of the 2000s and then applied to new data from the most recent few years available. When a classifier works perfectly, all of  the red bars in the separation plot will appear to the right of all o
the red bars in the separation plot will appear to the right of all o f the pink bars, and the black line denoting the probability of a “yes” case will jump from 0 to 1 at the point of separation. These classifiers aren’t perfect, but they seem to be working very well.
f the pink bars, and the black line denoting the probability of a “yes” case will jump from 0 to 1 at the point of separation. These classifiers aren’t perfect, but they seem to be working very well.
 Of course, what most of us want to do when we find a new data set is to see how it characterizes cases we know. We can do that here with heat maps of the confidence scores from the support vector machines. The maps below show the values from the most recent year available for t
Of course, what most of us want to do when we find a new data set is to see how it characterizes cases we know. We can do that here with heat maps of the confidence scores from the support vector machines. The maps below show the values from the most recent year available for t wo of the four regime types: 2012 for democracy and 2010 for military rule. These SVM confidence scores indicate the distance and direction of each case from the hyperplane used to classify the set of observations into 0s and 1s. The probabilities used in the separation plots are derived from them, but we choose to map the raw confidence scores because they exhibit more variance than the probabilities and are therefore easier to visualize in this form.
wo of the four regime types: 2012 for democracy and 2010 for military rule. These SVM confidence scores indicate the distance and direction of each case from the hyperplane used to classify the set of observations into 0s and 1s. The probabilities used in the separation plots are derived from them, but we choose to map the raw confidence scores because they exhibit more variance than the probabilities and are therefore easier to visualize in this form.
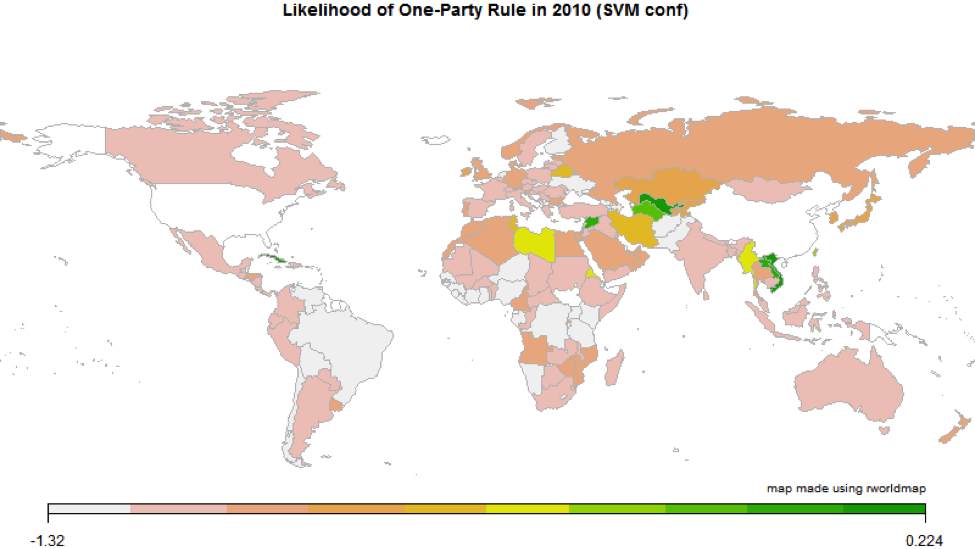
On the whole, cases fall out as we would expect them to. The democracy classifier confidently identifies Western Europe, Canada, Australia, and New Zealand as democracies; shows interesting variations in Eastern Europe and Latin America; and confidently identifies nearly all of the rest of the world as non-democracies (defined for this task as a Polity score of 10). Meanwhile, the military rule classifier sees Myanmar, Pakistan, and (more surprisingly) Algeria as likely  examples in 2010, and is less certain about the absence of military rule in several West African and Middle Eastern countries than in the rest of the world.
examples in 2010, and is less certain about the absence of military rule in several West African and Middle Eastern countries than in the rest of the world.
These preliminary results demonstrate that it is possible to generate probabilistic measures of regime type from publicly available texts at relatively low cost. That does not mean we’re fully satisfied with the output and ready to move to routine data production, however. For now, we’re looking at a couple of ways to improve the process.
First, the texts included in the relatively small corpus we have assembled so far only cover a narrow set of human-rights practices and political procedures. In future iterations, we plan to expand the corpus to include annual or occasional reports that discuss a broader range of features in each country’s national politics. Eventually, we hope to add news stories to the mix. If we can develop models that perform well on an amalgamation of occasional reports and news stories, we will be able to implement this process in near-real time, constantly updating probabilistic measures of regime type for all countries of the world at very low cost.
Second, the stringent criteria we used to observe each regime type in constructing the binary indicators on which the classifiers are trained also appear to be shaping the results in undesirable ways. We started this project with a belief that membership in these regime categories is inherently fuzzy, and we are trying to build a process that uses text mining to estimate degrees of membership in those fuzzy sets. If set membership is inherently ambiguous in a fair number of cases, then our approximation of a membership function should be bimodal, but not too neatly so. Most cases most of the time can be placed confidently at one end of the range of degrees of membership or the other, but there is considerable uncertainty at any moment in time about a non-trivial number of cases, and our estimates should reflect that fact.
If that’s right, then our initial estimates are probably too tidy, and we suspect that the stringent operationalization of each regime type in the training data is partly to blame. In future iterations, we plan to experiment with less stringent criteria—for example, by identifying a case as military rule if any of our sources tags it as such. With help from Sean J. Taylor, we’re also looking at ways we might use Bayesian measurement error models to derive fuzzy measures of regime type from multiple categorical data sets, and then use that fuzzy measure as the target in our machine-learning process.
So, stay tuned for more, and if you’ll be at APSA this week, please come to our Friday-morning panel and let us know what you think.
* NSF Award 1259190, Collaborative Research: Automated Real-time Production of Political Indicators
